これがウェブページフィルタエディタです。ここに、Proxomitron がウェブページを書き換えるためのマッチングルールを記述します。下図をクリックすると、それぞれの機能について解説が表示されます。
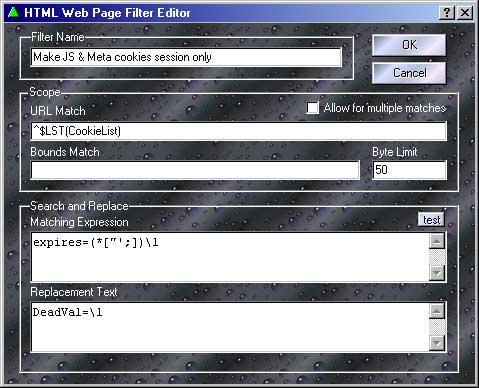
基本中の基本...
もっとも基本的なところでは、マッチングルールはワープロの「検索と置換」機能と同じように働きます。「Matching Expression(以下、検索表現)」にマッチしたテキストは「Replacement Text(以下、置換テキスト)」のテキストに置き換えられます。たとえば、検索表現に「Rimmer」、置換テキストに「That Smeghead」とすれば、ウェブページの「Rimmer」はすべて「That Smeghead」に書き換えられます。簡単でしょ?
これにマッチングルールを加えれば、かなり面白いことができます。
「<start>」 と 「<end>」
普通のテキスト置換やマッチングルールを使用した置換に加えて、検索表現には2つの特別な意味を持った値を使用することができます。<start> と <end>です。
<start> は、置換テキストの内容をウェブページの一番最初に付け加えます。JavaScript などをページに付け加えるのに使用してください。同様に、<end> は、ページの最後に何かを付け加えるために使用できます。
これらの特別な値を使用した場合には、bounds(以下、範囲制限)と byte limit(以下、バイト制限)は無視されます。これらの値を使用したルールが複数ある場合には、ウェブページフィルタリストと同じ順番で追加されていきます。
で、この Scope って何?
HTML では、タグが複数行にわたるのは珍しいことではありません。スコープセッティングを使うと、検索表現にマッチする最初の部分が見つかってから、どのくらいの範囲まで検索を続けるのかを設定できます。もしスコープがなければ、本当にマッチする部分がないのかどうか確かめるために、ページを始めから終わりまで調べなければならないでしょう。これでは、ページが完全に読み込み終わるまではブラウザに全くデータが送られないことになってしまいます。これはあまり良いやり方ではありません。ありがたいことに、HTMLの設計者は、タグに予測可能な「始まり」と「終わり」があるようにしてくれたので、話は少しだけ簡単になりました。
バイト制限と範囲制限は、どちらも検索する範囲を限定するために用いられます。
バイト制限 は、検索をあきらめるまでに最大で何バイトまで検索するのかを設定します。通常は、可能な限り小さな値を設定してください。ほとんどのタグでは、値は 128-256 か、さらに小さくてもいいくらいでしょう。もし、表現が正しいのにもかかわらずマッチしない場合には、この値を大きくしてください。ただし、あまり大きい値を設定すると、ブラウザに送る前に多くのデータを処理しなければならないため、ページの表示が遅くなる可能性があります。
どのくらいが最適なサイズかというのは、どのタグに関する問題なのか、ということに大きく左右されます。たとえば、「<Script ... </script>」タグは、何行にもわたる JavaScript を含んでいることが多いので、大きなバイト制限を必要とします。この場合であれば、4096 くらいの設定を試してみてください。
範囲制限 は、メインになる検索表現の範囲を、事前に絞り込むための表現です。通常、範囲制限は、アスタリスクを挟んだ始まりと終わりのタグで構成されます。たとえば、「<script * </script>」のように。検索表現として正しいものはすべてここで使用することができます。しかし、範囲制限は、可能な限りシンプルな方がいいでしょう。
範囲制限を使用するかどうかは任意です。多くの単純な検索表現では必要ないでしょう。けれども、複雑な検索表現になれば、これを使用することはパフォーマンスの向上につながります。メインの検索表現は、範囲制限にマッチした場合にだけチェックすればよくなるからです。さらに重要なことに、範囲制限は、あるルールが想定しているよりも多くのテキストにマッチしてしまうのを防ぐのに使えます。たとえば、リンクにマッチさせるつもりで以下のルールを作成したとしましょう...
Matching: <a * href="slugcakes.html" > * </a>
このルールを以下のテキストに対して適用すると...
<a href="crabcakes.html" > some stuff </a><br>
<a href="slugcakes.html" > other stuff </a>
最初のアスタリスクは上の 青 で表示された部分すべてにマッチするので、2番目のリンクだけではなく、両方 のリンクにマッチしてしまうのです! 「<a * </a>」のような範囲制限を使用することで、一度に一つずつリンクをチェックできるようになります。
検索表現と範囲制限
範囲制限 を使用しない場合は、検索表現の最初や最後には決してワイルドカードを置かないでください(たとえば、「*foo* 」のように)。これは バイト制限 で設定された文字数をひとまとめにマッチしてしまいます。普通はこんな動作を期待しないでしょう。
範囲制限 を使用する場合は、状況は変わります。範囲制限が、検索されるテキストの範囲を選択するからです。検索表現は全体として、範囲制限がマッチしたもの全部 にマッチしなければなりません。これを実現する最も簡単な方法は、表現の最初と最後にワイルドカードを使うことです。変数を使うことができるので(たとえば「\1 foo \2」のように)、タグでマッチさせた部分の周りのテキストを取り込んで、置換テキストで使うことができます。
以下は次のようなリンクにマッチさせる場合の例です: <a href="http://somewhere"> some text </a>
| Bounds | : <a\s*</a> | Limit: 128 |
| Matching | : * href="\1" * | |
| Replace | : <a href="\1"> some new link next </a> | |
URL Match - 別の種類の範囲コントロール
あるフィルタを特定のページだけで適用するために、URLマッチ を使用することができます。マッチングルールはすべて使用することができますので、URLの一部だけをマッチさせるだけでかまいません。複数のページを記述する場合も、ORシンボルの「 | 」を使って並べていくことができます。たとえば、「 www.this.com|www.this.too.com 」といったように。また逆に、否定の表現である「 (^...) 」の形を用いることで、特定のページをフィルタの適用から除外することができます。たとえば、「 (^www.not.this.page) 」といったように。
注意してほしいのですが、URL の「 http:// 」の部分は、マッチングの前に取り除かれますので、記述する必要はありません。
 もし、大量の URL を扱う必要があったり、同じ URL を複数のフィルタで使い回したい場合、ブロックファイルを使用することができます。たとえば、「MyURLs」というブロックリストを作成したとしましょう。もし、このリストに記述されたサイトだけにフィルタを適用させたい場合、そのフィルタの URL マッチに $LST(MyURLs) と記述すればいいのです。また、ブロックリストに記述されたサイト 以外 のサイトにそのフィルタを適用させたい場合、NOT の表現を用いて (^$LST(MyURLs)) のように記述することができます。また、URLマッチの上で右クリックすることで、自動的にブロックリストのコマンドを挿入したり、リストを編集したりすることのできるコンテキストメニューが表示されます。
もし、大量の URL を扱う必要があったり、同じ URL を複数のフィルタで使い回したい場合、ブロックファイルを使用することができます。たとえば、「MyURLs」というブロックリストを作成したとしましょう。もし、このリストに記述されたサイトだけにフィルタを適用させたい場合、そのフィルタの URL マッチに $LST(MyURLs) と記述すればいいのです。また、ブロックリストに記述されたサイト 以外 のサイトにそのフィルタを適用させたい場合、NOT の表現を用いて (^$LST(MyURLs)) のように記述することができます。また、URLマッチの上で右クリックすることで、自動的にブロックリストのコマンドを挿入したり、リストを編集したりすることのできるコンテキストメニューが表示されます。
また、URLマッチのコンテキストメニューには、URLマッチをテストすることのできるオプションがあることにも気が付くと思います。これは フィルタテスト と同じように使うことができ、あるURLがマッチするかどうかテストすることができます。
「Allow for multiple matches」 を使うとどうなるの?
通常、あるルールがマッチすると、その結果は直接ブラウザに送られます。マッチした部分が、別のルールに再びマッチすることはありません。これは主に効率の面からそうするようになっています。実際かなりの仕事量の節約になりますが、同時に、あるフィルタを他のフィルタよりも優先的に適用するためにも使うことができます。つまり早い者勝ち、の法則です。
しかし、このことは必ずしも有効とは言えません。たとえば、「 <Body ... > 」タグについて考えてみましょう。このタグはしばしば、複数の、しかも互いに無関係な要素が含まれていて、それを変更したいことがあります。仮に、ここに2つのルールがあるとしてみましょう。ひとつはデフォルトの文字色を変更し、もうひとつは背景画像を変更するというルールです。この場合、問題が発生します。最初のルールが、マッチした <Body> タグを消費してしまうので、別のルールがマッチできないのです。そのため、「allow for multiple matches」の設定ができました。これがチェックされた場合、マッチして処理した結果を、再び処理用のバッファに戻しますので、他のルールをさらに適用することができます。上記の例では、最初のルールでこの設定を有効にしておけば、2番目のルールもマッチするようになります。
この設定は使いすぎないようにしてください。非常にパワフルですが、通常よりも多くの処理を必要とします。そして注意深く扱わなければ、「無限の」 マッチングに陥ってしまうことになります。
次のような例を考えてみてください。「『 frog 』という文字列を検索し、『 The evil frog must die! 』に置き換える」。 全然問題ないようにみえるでしょう? でも、このルールが「multiple matches」の設定を有効にして適用されたとしたら、置換テキストに「frog」があるので、このルールは自分の出力に再びマッチしてしまうことになります。そして、frog が無限に異常発生してしまうことになるでしょう! どうしてかって? つまり、まずルールが「frog」を見つけると、そこに「The evil frog must die!」を挿入します。単純ですね。しかし、マッチした場所から続けて「frog」を検索するので、新しい「frog」にマッチしてしまい、この処理が延々と繰り返されます。解決法ですか? そうですね、もし「frog」が、置換テキストの最初にあれば、こんなことは起こらないでしょう。次の検索は常に1文字後ろから始まります ので、「frog」の代わりに「rog」が見つかるだけになるでしょう。とにかく、この設定を用いてルールを作る際には、検索表現が置換テキスト(から最初の1文字をのぞいたもの)にマッチしないようにしてください。そうすれば、すべてうまくいくでしょう。
 Return to main index
Return to main index